Better & Faster Large Language Models via Multi-token Prediction
motivation 训练和推理阶段对比
传统方法的问题(预测下一个token):#card
训练阶段:token-by-token生成,是一种感知局部的训练方法,难以学习长距离的依赖关系。
推理阶段:逐个token生成,推理速度较慢
MTP方法(一次预测多个token):
训练阶段:#card
通过预测多步token,迫使模型学到更长的token依赖关系,从而更好理解上下文,避免陷入局部决策的学习模式。
同时一次预测多个token,可大大提高样本的利用效率,相当于一次预估可生成多个<predict, label>样本,来更新模型,有助于模型加速收敛。
推理阶段:#card
- 并行预估多个token,可提升推理速度
共享 Transformer 的主网络,接入 4 个并行预估头,然后输出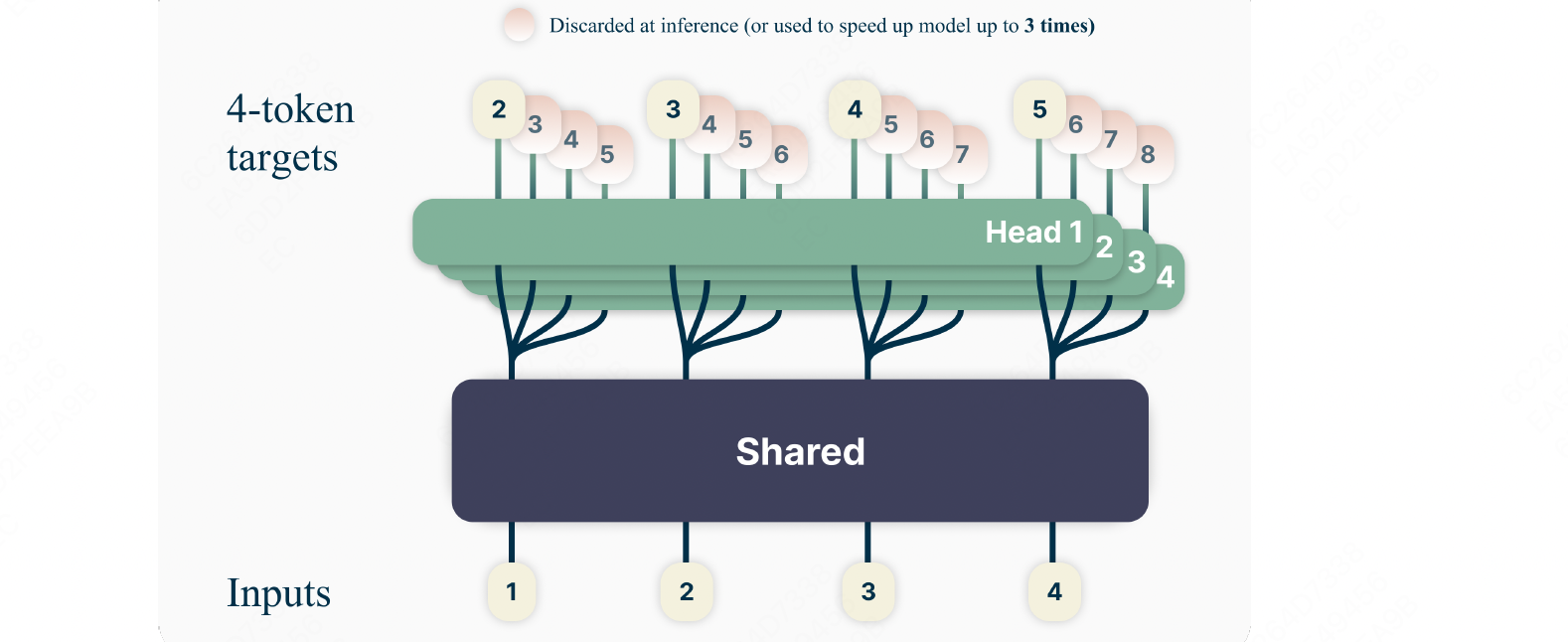
主干网络就是训练好的decoder-only的多层Transformer的网络,#card
$t$ 个输入token $x_{t: 1}=x_t, \ldots, x_1$ 经过主干网络计算,最终输出隐层表示:$z_{t: 1}$(来自于 $x_{t: 1}$ 编码结果)。
$z_{t: 1}$ 上面接了多输出Head,每个Head负责预估一个token, ${ Head}_1$ 负责预估 next token, $\mathrm{Head}_2$ 负责预估 next next token,以此类推
Head 是一个Transformer层(包括 MHA+2层FFN),#card
- 且每个Head的Transformer层是独立的,非共享的,经过这层处理后的结果记作:$f_{h_i}\left(z_{t: i}\right)$
最后再将 $f_{h_i}\left(z_{t: i}\right)$ 送入到词表投影层( $f_u$ 包括1个投影矩阵+1个Softmax),预估每个词的概率分布。#card
最终通过某种采样方法(如:greedy,beam search等)生成token。
注意,这个词表投影层是原预训练网络(original model)的投影矩阵+Softmax,多Head是共享的。
[[@deepseek技术解读(2)-MTP(Multi-Token Prediction)的前世今生]] 重新画图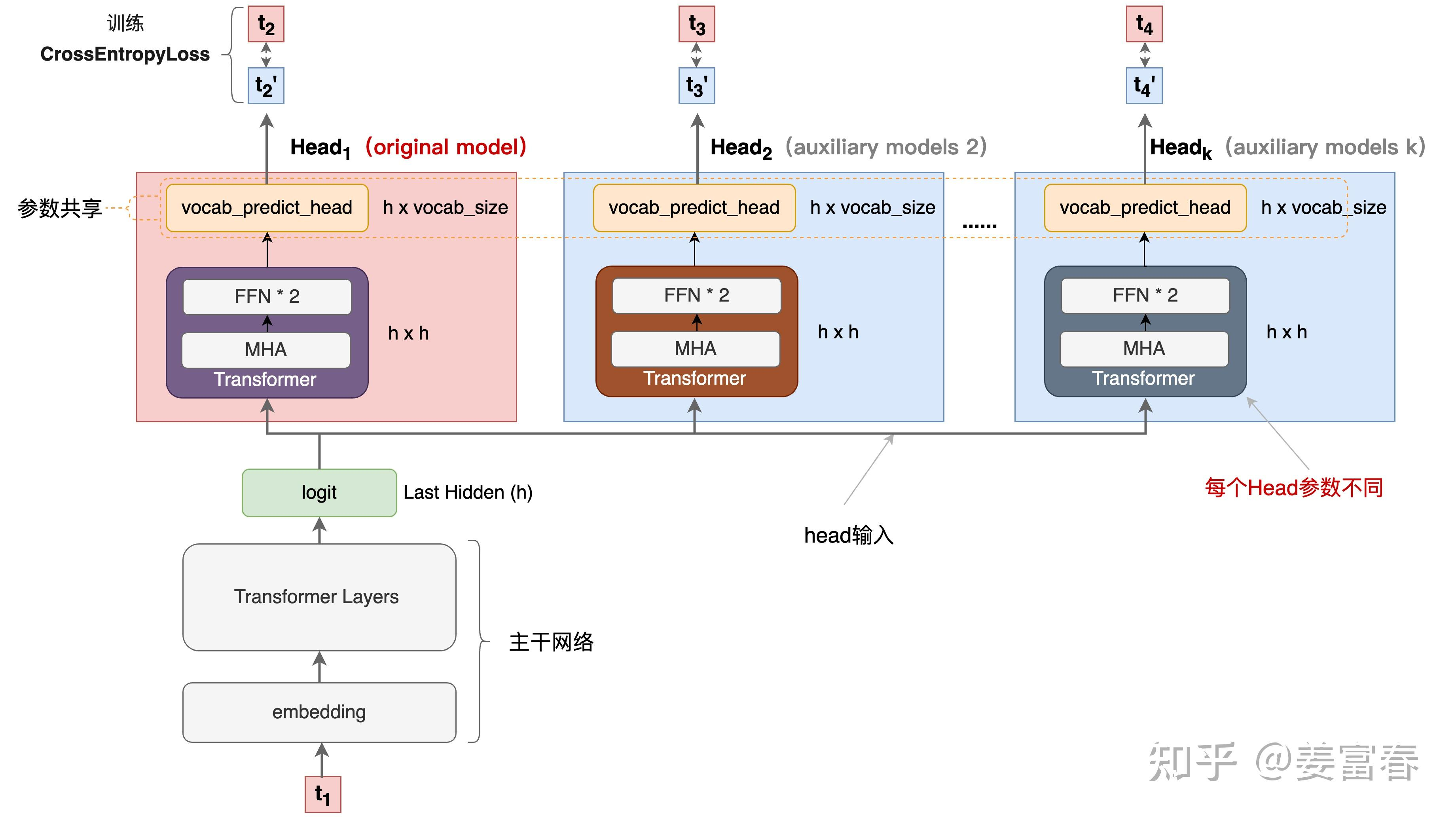
和 [[Blockwise Parallel Decoding for Deep Autoregressive Models]] 区别#card
图2是2层FFN, 图6是一个Transformer
图6 除了可按图2方法一样可做并行推理,本文也重点考虑模型加速训练的优化,在模型训练时,多个头都会并行计算loss时,提升样本利用效率和加速模型收敛。
Better & Faster Large Language Models via Multi-token Prediction